使用 Python 解題樹的走訪
分類
說明
在 Youtube 上看到一部模擬軟體工程師面試的影片,挑戰的面試者是台灣人,在軟體公司擔任技術總監,在影面中面試官出了一題是關於樹的走訪,並且資料需透過 API 取得,面試官只把題目、功能、和想要的結果告訴面試者,我們一起來討論這次的題目和面試者的表現狀況如何。
題目說明
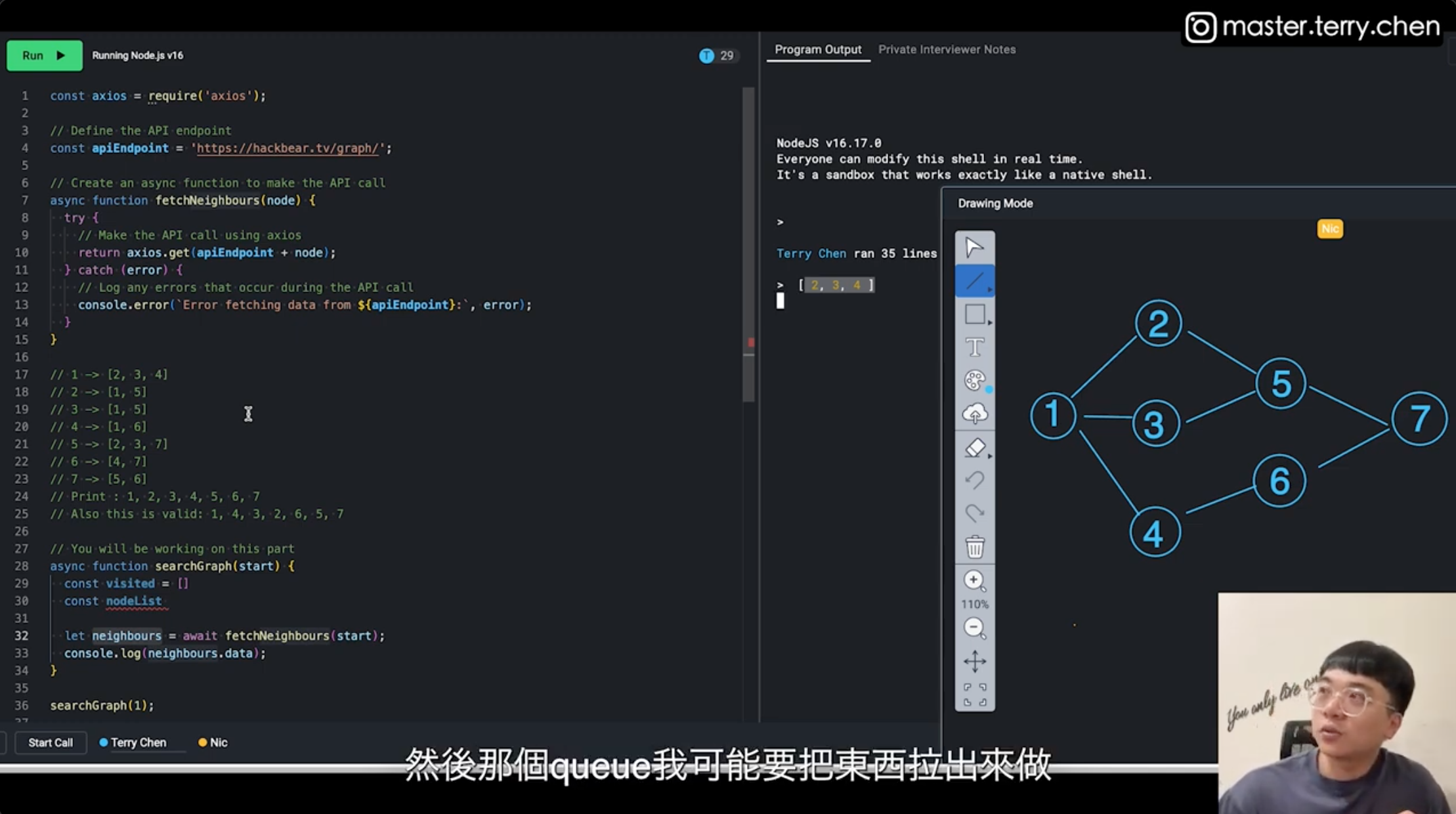
詳細的題目說明請參考原影片 誠徵資深實習生|面試過程公開
如圖所示,題目要求要走訪右側的樹狀圖,走訪順序需按層數走訪,同一層的走訪順序不限。
例如:
第1層: 1
第2層: (2, 3, 4) 或 (2, 4, 3) 或 (3, 2, 4) 等等
第3層: (5, 6) 或 (6, 5)
第4層: 7
API 回傳的範例在上圖左側的註解中,此方法會回傳節點的鄰居,如下所示
1的鄰居(2, 3, 4)
2的鄰居(1, 5)
3的鄰居(1, 5)
使用 ChatGPT 協助解題過程
首先我們先使用 ChatGPT 給我們初步的解答。
提問
請用 python 給我一個 fetchNumber(node) 方法
定義以下的樹狀圖
第1層 1
第2層 2 3 4
第3層 5 6
第4層 7
1 的鄰居 2,3,4
2 的鄰居 1,5
3 的鄰居 1,5
4 的鄰居 1,6
5 的鄰居 2,3,7
6 的鄰居 4,7
7 的鄰居 5,6
當 node=1, return [2,3,4]
當 node=2, return [1,5]
依此類推,並且此方法回 delay 1 秒才 return
回答
import time
# 定義樹狀結構
tree = {
1: [2, 3, 4],
2: [1, 5],
3: [1, 5],
4: [1, 6],
5: [2, 3, 7],
6: [4, 7],
7: [5, 6]
}
# 定義 fetchNumber 方法,根據指定的節點返回鄰居列表
def fetchNumber(node):
time.sleep(1) # 模擬 delay
return tree[node]
# 測試
print(fetchNumber(1)) # 預期輸出 [2, 3, 4]
print(fetchNumber(2)) # 預期輸出 [1, 5]
提問
請使用 python 給我一個走訪上述樹狀資料結構
的方法 search_graph(start),假設 start 永遠都是1即可
走訪順序需按層數走訪,同一層的走訪順序不限
並且注意因為 fetchNumber 會 delay 1秒
所以請先用非同步的方式取得資料後再處理遍歷以節省程式等待時間。
第1層 1
第2層 2 3 4
第3層 5 6
第4層 7
search_graph(1) 預期輸出 1 2 3 4 5 6 7 的走訪
或者 1 4 3 2 6 5 7 也是正確的結果
回答
import asyncio
graph = {
1: [2, 3, 4],
2: [1, 5],
3: [1, 5],
4: [1, 6],
5: [2, 3, 7],
6: [4, 7],
7: [5, 6]
}
async def fetchNumber(node):
await asyncio.sleep(1) # 模擬耗時的操作
return graph[node]
async def search_graph(start):
queue = [start]
visited = {start}
while queue:
node = queue.pop(0)
print(node, end=' ')
neighbors = await fetchNumber(node)
for n in neighbors:
if n not in visited:
visited.add(n)
queue.append(n)
asyncio.run(search_graph(1))
後面接著提問如何節省 search_graph 等待時間以及相關的問題,這裡我就忽略不再繼續寫。
整理程式
從 ChatGPT 已經得到可執行的解答了,已經算可以交付答案了,但面試官後面會詢問有沒有辦法讓程式運行的再快一點,所以這裡我直接給出了優化過後程式,在並行執行的部分 ChatGPT 比較難一次性給出解答,我得自己切分問題後稍微整理程式才能正常運行。
from asyncio import sleep
from asyncio import gather
from asyncio import run
async def fetch_neighbors(node: int) -> list[int]:
"""取得鄰居節點
Args:
node (int): 節點
Returns:
list[int]: 鄰居節點
"""
graph = {
1: [2, 3, 4],
2: [1, 5],
3: [1, 5],
4: [1, 6],
5: [2, 3, 7],
6: [4, 7],
7: [5, 6],
}
# 模擬延遲
await sleep(1)
return graph[node]
async def gather_neighbors(nodes: list[int]) -> dict[int, list[int]]:
"""一次取得多個節點的鄰居
Args:
nodes (list[int]): 節點串列
Returns:
dict[int, list[int]]: 多個節點鄰居
"""
coroutines = [fetch_neighbors(node) for node in nodes]
results = await gather(*coroutines)
return dict(zip(nodes, results))
async def search_graph(start: int):
"""走訪樹狀圖
Args:
start (int): 根節點
"""
queue = [start]
visited = {start}
while queue:
nodes_list = await gather_neighbors(queue)
queue = []
for nodes in nodes_list.values():
for node in nodes:
if node not in visited:
visited.add(node)
queue.append(node)
print(visited)
run(search_graph(1))
上述程式設計的概念為從根節點1開始走訪,接著將下一次要走訪的節點儲存在 queue 變數中,在 gather_neighbors() 使用 gather() 方法一次性取得所有的鄰居節點,可以節省一些時間,將未走訪的節點儲存到 visited 變數中,一直重複直到 queue 為空串列為止。
search_graph() Big O
計算時間複雜度對我來說不是一件容易的事情,在我學習演算法時,學到的時間複雜度計算最多就是 1, n, log n, n^2 都是以類似 print() 次數來講解,但實際上卻有很多事情我卻沒有學習到,例如我在計算 A() 時,有呼叫 B(),在 B() 中使用兩層 for 迴圈 n^2,這樣我在計算 A() 時我是否應該要把呼叫的 B() 當作 n^2?還有其他許多的問題我都沒有深入去瞭解。
在這裡一樣透過 ChatGPT 看他會怎麼回答。
提問
略過複製貼上的程式...
請幫我分析 search_graph 時間複雜度
這個程式的時間複雜度取決於 search_graph 函數中 while 迴圈執行的次數。
while 迴圈每次從 queue 取出節點,然後使用 gather_neighbors 函數
取得這些節點的鄰居,接著將這些鄰居加入 queue,直到 queue 為空為止。
假設樹狀圖有 $n$ 個節點,則 while 迴圈最多執行 $n-1$ 次
因為最後一個節點不需要再取得鄰居。
每次 while 迴圈中使用 gather_neighbors 函數取得節點的鄰居時,
會建立一個長度為 $k$ 的 coroutine 陣列,
其中 $k$ 為節點的平均度數。這些 coroutine 會並行執行,
所以執行時間不會影響時間複雜度,因此可以忽略。所以總時間複雜度為 $O(n)$。
因此,search_graph 函數的時間複雜度為 $O(n)$。
ChatGPT 給出的答案是 O(n),跟我預期的不同,因為我原本想 while 底下兩個 for 迴圈,至少也要 n^3 起跳,但看一下 ChatGPT 給的答案也很合理,我不確定 ChatGPT 計算的 時間複雜度是否正確,如果有誤,請私訊告訴我。
面試過程
首先我先告訴大家,這不是非常困難題目,對於我來說他比簡單題目再稍微困難一點,算是比較麻煩的簡單題目,在學過資料結構和演算法來說這算是基礎題。
一開始面試官只有簡單講解題目、功能、和想要的結果,面試官在講解題目的過程有意避開演算法和資料結構的概念,這是因為他想聽到面試者是否會告訴他這些概念。
面試者一開始先釐清問題需求,算是有經驗的作法,接下來面試者一邊解釋他要設計的程式方向,一邊更新程式,在過程中,面試官會刻意詢問資料結構和演算法相關的問題。
在面試時多少會造成面試者一些壓力,在面試者提出想要 Google 搜尋問題時,面試官接受,並說不能太多,給予面試者一些壓力,還有編輯器並沒有自動提示功能,這會使編程難度大大提升。
面試者忘記 stack queue 等相關知識,並在運行程式時出現多次錯誤訊息和跑出一次無窮迴圈,這些也許會被面試官心裡扣分。
最後面試者有順利寫出可如期運行的程式,算是有通過基本的面試要求,如果題解不出來,那麼一定會被解的出題的其他面試者輾壓下去。
後面面試官額外問了衍伸的問題,他想讓程式跑快一點,因為他一眼就看出程式浪費很多時間在等待,在說明的過程的,無意發現面試者忘記 Big O,但也許這並不會太嚴重,只要面試者可以告訴他如何讓程式跑快一點,仍然算是個有戰力的員工。
最後面試者有回答出預期的答案來優化程式,雖然並不是清楚、準確,但方向是對的。
面試官覺得這次面試還算可以,因為面試官期望的面試者是這樣的:這是一個基礎的樹的走訪,只要這樣寫就行了。他期望面試者輕鬆回答題目,就好像送分題一樣輕鬆,而不是思考半天,又跑錯好幾次程式。
以上只是我個人分析、猜測,並不代表他們真實的想法就是如此。
總結
以這樣的面試確實還算不錯,該解的題目有解出,並且回答的大方向都還行,在網路上看到很多人不認同技術總監的能力不該如此,甚至嘲笑對方,實際上我們都會忘記一些概念,又或者說我們不可能把所以的軟體知識都記在腦海裡,面試者說忘記 Big O 時,確實我自己心裡也是想著:台灣技術總監連 Big O 都忘記有夠好笑,但我們必須知道一個人的優點和缺點,而不是放大對方的缺點去嘲笑對方,在這裡面試官做出很好的示範,給予對方尊重,並客觀分析面試者的能力。
參考
一杯咖啡的力量,勝過千言萬語的感謝。
支持我一杯咖啡,讓我繼續創作優質內容,與您分享更多知識與樂趣!